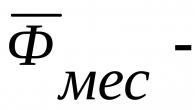.
.
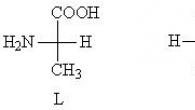
À l’inverse, si est un a.e non négatif. fonctionner de telle sorte que  , alors il existe une mesure de probabilité absolument continue sur telle que c'est sa densité.
, alors il existe une mesure de probabilité absolument continue sur telle que c'est sa densité.
Remplacement de la mesure dans l'intégrale de Lebesgue :
 ,
,
où est toute fonction Borel intégrable par rapport à la mesure de probabilité.
Dispersion, types et propriétés de dispersion Le concept de dispersion
Dispersion dans les statistiques se trouve comme l'écart type des valeurs individuelles de la caractéristique au carré de la moyenne arithmétique. En fonction des données initiales, elle est déterminée à l'aide des formules de variance simples et pondérées :
1. Variation simple(pour les données non groupées) est calculé à l'aide de la formule :
![]()
2. Variance pondérée (pour les séries de variations) :

où n est la fréquence (répétabilité du facteur X)
Un exemple de recherche de variance
Cette page décrit un exemple standard de recherche de variance, vous pouvez également examiner d'autres problèmes pour la trouver.
Exemple 1. Détermination du groupe, de la moyenne du groupe, de l'intergroupe et de la variance totale
Exemple 2. Trouver la variance et le coefficient de variation dans un tableau de regroupement
Exemple 3. Trouver la variance dans une série discrète
Exemple 4. Les données suivantes sont disponibles pour un groupe de 20 étudiants par correspondance. Il est nécessaire de construire une série d'intervalles de distribution de la caractéristique, de calculer la valeur moyenne de la caractéristique et d'étudier sa dispersion

Construisons un regroupement d'intervalles. Déterminons la plage de l'intervalle à l'aide de la formule :
![]()
où X max est la valeur maximale de la caractéristique de regroupement ; X min – valeur minimale de la caractéristique de regroupement ; n – nombre d'intervalles :
Nous acceptons n=5. Le pas est : h = (192 - 159)/ 5 = 6,6
Créons un regroupement d'intervalles

Pour d'autres calculs, nous construirons un tableau auxiliaire :

X"i – le milieu de l'intervalle. (par exemple, le milieu de l'intervalle 159 – 165,6 = 162,3)
Nous déterminons la taille moyenne des élèves à l'aide de la formule de moyenne arithmétique pondérée :

Déterminons la variance à l'aide de la formule :
La formule peut être transformée comme ceci :

De cette formule il résulte que la variance est égale à la différence entre la moyenne des carrés des options et le carré et la moyenne.
Dispersion dans les séries de variationsà intervalles égaux en utilisant la méthode des moments peut être calculé de la manière suivante en utilisant la deuxième propriété de dispersion (en divisant toutes les options par la valeur de l'intervalle). Détermination de l'écart, calculé selon la méthode des moments, la formule suivante est moins laborieuse :

où i est la valeur de l'intervalle ; A est un zéro conventionnel, pour lequel il convient d'utiliser le milieu de l'intervalle de fréquence la plus élevée ; m1 est le carré du moment du premier ordre ; m2 - moment du deuxième ordre
Variance des traits alternatifs (si dans une population statistique une caractéristique change de telle manière qu'il n'y a que deux options mutuellement exclusives, alors cette variabilité est appelée alternative) peut être calculée à l'aide de la formule :

En substituant q = 1- p dans cette formule de dispersion, nous obtenons :

Types de variance
Écart total mesure la variation d’une caractéristique dans l’ensemble de la population sous l’influence de tous les facteurs qui provoquent cette variation. Elle est égale au carré moyen des écarts des valeurs individuelles d'une caractéristique x par rapport à la valeur moyenne globale de x et peut être définie comme variance simple ou variance pondérée.
Variation au sein du groupe caractérise la variation aléatoire, c'est-à-dire partie de la variation qui est due à l'influence de facteurs non pris en compte et ne dépend pas de l'attribut facteur qui constitue la base du groupe. Une telle dispersion est égale au carré moyen des écarts des valeurs individuelles de l'attribut au sein du groupe X par rapport à la moyenne arithmétique du groupe et peut être calculée comme une dispersion simple ou comme une dispersion pondérée.
Ainsi, mesures de variance au sein du groupe variation d'un trait au sein d'un groupe et est déterminé par la formule :

où xi est la moyenne du groupe ; ni est le nombre d'unités dans le groupe.
Par exemple, les variances intragroupe qui doivent être déterminées dans le cadre de l'étude de l'influence des qualifications des travailleurs sur le niveau de productivité du travail dans un atelier montrent des variations de production dans chaque groupe causées par tous les facteurs possibles (état technique de l'équipement, disponibilité des équipements). outils et matériaux, âge des travailleurs, intensité de travail, etc.), à l'exception des différences de catégorie de qualification (au sein d'un groupe, tous les travailleurs ont les mêmes qualifications).
La moyenne des variances au sein d'un groupe reflète la variation aléatoire, c'est-à-dire la partie de la variation qui s'est produite sous l'influence de tous les autres facteurs, à l'exception du facteur de regroupement. Il est calculé à l'aide de la formule :

Variance intergroupe caractérise la variation systématique de la caractéristique résultante, qui est due à l'influence du facteur-signe, qui constitue la base du groupe. Il est égal au carré moyen des écarts des moyennes de groupe par rapport à la moyenne globale. La variance intergroupe est calculée à l'aide de la formule :

Les principaux indicateurs généralisants de variation des statistiques sont les dispersions et les écarts types.
Dispersion ceci moyenne arithmétique écarts carrés de chaque valeur caractéristique par rapport à la moyenne globale. La variance est généralement appelée carré moyen des écarts et est notée 2. Selon les données sources, la variance peut être calculée à l'aide de la moyenne arithmétique simple ou pondérée :
variance non pondérée (simple) ;
 variance pondérée.
variance pondérée.
Écart-type c'est une caractéristique généralisatrice des tailles absolues variantes signes dans l’ensemble. Il est exprimé dans les mêmes unités de mesure que l'attribut (en mètres, tonnes, pourcentage, hectares, etc.).
L'écart type est la racine carrée de la variance et est noté :
 écart type non pondéré ;
écart type non pondéré ;
 écart type pondéré.
écart type pondéré.
L'écart type est une mesure de la fiabilité de la moyenne. Plus l’écart type est petit, plus la moyenne arithmétique reflète l’ensemble de la population représentée.
Le calcul de l'écart type est précédé du calcul de la variance.
La procédure de calcul de la variance pondérée est la suivante :
1) déterminer la moyenne arithmétique pondérée :
2) calculer les écarts des options par rapport à la moyenne :
3) mettre au carré l'écart de chaque option par rapport à la moyenne :
4) multiplier les carrés des écarts par des poids (fréquences) :
5) résumer les produits obtenus :
![]()
6) le montant obtenu est divisé par la somme des poids :

Exemple 2.1

Calculons la moyenne arithmétique pondérée :

Les valeurs des écarts par rapport à la moyenne et leurs carrés sont présentés dans le tableau. Définissons la variance :

L'écart type sera égal à :

Si les données sources sont présentées sous forme d'intervalle série de distribution , vous devez d'abord déterminer la valeur discrète de l'attribut, puis appliquer la méthode décrite.
Exemple 2.2
Montrons le calcul de la variance pour une série d'intervalles à l'aide de données sur la répartition de la superficie ensemencée d'une ferme collective en fonction du rendement en blé.

La moyenne arithmétique est :

Calculons la variance :

6.3. Calcul de la variance à l'aide d'une formule basée sur des données individuelles
Technique de calcul écarts complexe, et avec de grandes valeurs d'options et de fréquences, cela peut être fastidieux. Les calculs peuvent être simplifiés en utilisant les propriétés de dispersion.
La dispersion a les propriétés suivantes.
1. Réduire ou augmenter les poids (fréquences) d’une caractéristique variable d’un certain nombre de fois ne modifie pas la dispersion.
2. Diminuer ou augmenter chaque valeur d'une caractéristique du même montant constant UN ne change pas la dispersion.
3. Diminuer ou augmenter chaque valeur d'une caractéristique d'un certain nombre de fois k respectivement réduit ou augmente la variance de k 2 fois écart-type dans k une fois.
4. La dispersion d'une caractéristique par rapport à une valeur arbitraire est toujours supérieure à la dispersion par rapport à la moyenne arithmétique par carré de la différence entre la moyenne et les valeurs arbitraires :
![]()
Si UN 0, alors on arrive à l’égalité suivante :
c'est-à-dire que la variance de la caractéristique est égale à la différence entre le carré moyen des valeurs caractéristiques et le carré de la moyenne.
Chaque propriété peut être utilisée indépendamment ou en combinaison avec d'autres lors du calcul de la variance.
La procédure de calcul de la variance est simple :
1) déterminer moyenne arithmétique :
2) mettre au carré la moyenne arithmétique :

3) au carré l'écart de chaque variante de la série :
X je 2 .
4) trouver la somme des carrés des options :
5) diviser la somme des carrés des options par leur nombre, c'est-à-dire déterminer le carré moyen :
6) déterminer la différence entre le carré moyen de la caractéristique et le carré de la moyenne :
Exemple 3.1 Les données suivantes sont disponibles sur la productivité des travailleurs :

Faisons les calculs suivants :
![]()
Solution.
Comme mesure de dispersion des valeurs de variables aléatoires, nous utilisons dispersion
La dispersion (le mot dispersion signifie « diffusion ») est mesure de dispersion de valeurs de variables aléatoires par rapport à son espérance mathématique. La dispersion est l'espérance mathématique de l'écart carré d'une variable aléatoire par rapport à son espérance mathématique.
Si la variable aléatoire est discrète avec un ensemble de valeurs infini mais dénombrable, alors
si la série du côté droit de l’égalité converge.
Propriétés de dispersion.
- 1. La variance d'une valeur constante est nulle
- 2. La variance de la somme des variables aléatoires est égale à la somme des variances
- 3. Le facteur constant peut être soustrait du signe de la dispersion au carré
La variance de la différence des variables aléatoires est égale à la somme des variances
Cette propriété est une conséquence des deuxième et troisième propriétés. Les écarts ne peuvent que s’additionner.
Il est pratique de calculer la dispersion à l'aide d'une formule qui peut être facilement obtenue en utilisant les propriétés de dispersion
La variance est toujours positive.
La variance a dimension dimension carrée de la variable aléatoire elle-même, ce qui n'est pas toujours pratique. Par conséquent, la quantité
Écart-type(écart type ou standard) d'une variable aléatoire est la valeur arithmétique de la racine carrée de sa variance
Jetez deux pièces de 2 et 5 roubles. Si la pièce atterrit sous la forme d'un blason, alors zéro point est attribué, et si elle atterrit sous la forme d'un nombre, alors le nombre de points est égal à la dénomination de la pièce. Trouvez l'espérance mathématique et la variance du nombre de points.
Solution. Trouvons d'abord la distribution de la variable aléatoire X - le nombre de points. Toutes les combinaisons - (2;5),(2;0),(0;5),(0;0) - sont équiprobables et la loi de distribution est :

Valeur attendue:
On trouve la variance en utilisant la formule
pourquoi calculons-nous
Exemple 2.
Trouver une probabilité inconnue R., espérance mathématique et variance d'une variable aléatoire discrète spécifiée par un tableau de distribution de probabilité
On trouve l'espérance mathématique et la variance :
M(X) = 00,0081 + 10,0756 + 20,2646 + 3 0,4116 + +40,2401=2,8
Pour calculer la dispersion, nous utilisons la formule (19.4)
D(X) = 020 ,0081 + 120,0756 + 220,2646 + 320,4116 + 420,2401 - 2,82 = 8,68 -

Exemple 3. Deux athlètes de même force organisent un tournoi qui dure soit jusqu'à la première victoire de l'un d'eux, soit jusqu'à ce que cinq matchs aient été joués. La probabilité de gagner un match pour chacun des athlètes est de 0,3 et la probabilité d'un match nul est de 0,4. Trouvez la loi de distribution, l'espérance mathématique et la dispersion du nombre de jeux joués.
Solution. Valeur aléatoire X- le nombre de parties jouées, prend des valeurs de 1 à 5, soit
Déterminons les probabilités de terminer le match. Le match se terminera au premier set si l'un de leurs athlètes gagne. La probabilité de gagner est
R.(1) = 0,3+0,3 =0,6.
S'il y a match nul (la probabilité d'un match nul est de 1 - 0,6 = 0,4), alors le match continue. Le match se terminera lors du deuxième match si le premier était nul et que quelqu'un gagnait le second. Probabilité
R.(2) = 0,4 0,6=0,24.
De même, le match se terminera au troisième match s'il y a eu deux matchs nuls d'affilée et que quelqu'un a encore gagné.
R.(3) = 0,4 0,4 0,6 = 0,096. R.(4)= 0,4 0,4 0,4 0,6=0,0384.
Le cinquième jeu est le dernier de toutes les variantes.
R.(5)= 1 - (R.(1)+R.(2)+R.(3)+R.(4)) = 0,0256.
Mettons tout dans un tableau. La loi de distribution de la variable aléatoire « nombre de parties gagnées » a la forme
Valeur attendue
Nous calculons la variance à l'aide de la formule (19.4)
Distributions discrètes standards.
Distribution binomiale. Laissez le schéma expérimental de Bernoulli être mis en œuvre : n expériences indépendantes identiques, dans chacune desquelles l'événement UN peut apparaître avec une probabilité constante p et n'apparaîtra pas avec probabilité
(voir leçon 18).
Nombre d'occurrences de l'événement UN dans ces n expériences, il existe une variable aléatoire discrète X, dont les valeurs possibles sont :
0; 1; 2; ... ;m; ... ; n.
Probabilité d'apparition mévénements A dans une série spécifique de n les expériences avec et la loi de distribution d'une telle variable aléatoire sont données par la formule de Bernoulli (voir cours 18)
 |



Caractéristiques numériques d'une variable aléatoire X distribué selon la loi binomiale :

Si n est génial (), alors, quand, la formule (19.6) entre dans la formule
et la fonction gaussienne tabulée (le tableau des valeurs de la fonction gaussienne est donné à la fin du cours 18).
En pratique, ce n’est souvent pas la probabilité d’occurrence qui importe. mévénements UN dans une série spécifique de n expériences et la probabilité que l'événement UN rien de moins n'apparaîtra
fois et pas plus de fois, c'est-à-dire la probabilité que X prenne les valeurs
Pour ce faire, nous devons résumer les probabilités
Si n est génial (), alors, quand, la formule (19.9) se transforme en une formule approximative

fonction tabulée. Des tableaux sont fournis à la fin de la leçon 18.
Lors de l'utilisation de tableaux, il faut tenir compte du fait que
Exemple 1. Une voiture à l’approche d’une intersection peut continuer à rouler sur l’une des trois routes suivantes : A, B ou C avec une probabilité égale. Cinq voitures s'approchent de l'intersection. Trouvez le nombre moyen de voitures qui circuleront sur la route A et la probabilité que trois voitures circulent sur la route B.
Solution. Le nombre de voitures qui circulent sur chaque route est une variable aléatoire. Si l'on suppose que toutes les voitures s'approchant de l'intersection se déplacent indépendamment les unes des autres, alors cette variable aléatoire est distribuée selon la loi binomiale avec
n= 5 et p = .
Par conséquent, le nombre moyen de voitures qui suivront la route A est selon la formule (19.7)
et la probabilité souhaitée à
Exemple 2. La probabilité de défaillance de l'appareil lors de chaque test est de 0,1. 60 tests de l'appareil sont effectués. Quelle est la probabilité qu'une panne d'appareil se produise : a) 15 fois ; b) pas plus de 15 fois ?
UN. Puisque le nombre de tests est de 60, nous utilisons la formule (19,8)
D'après le tableau 1 de l'annexe à la leçon 18, nous trouvons
b. Nous utilisons la formule (19.10).
D'après le tableau 2 de l'annexe à la leçon 18
- - 0,495
- 0,49995
Distribution de Poisson) loi des événements rares). Si n grand et R. peu (), et le produit etc. conserve une valeur constante, que l'on note l,
alors la formule (19.6) devient la formule de Poisson

La loi de distribution de Poisson a la forme :

Évidemment, la définition de la loi de Poisson est correcte, car propriété principale d'une série de distribution
C'est fait, parce que somme de séries
Le développement en série de la fonction à
Théorème. L'espérance mathématique et la variance d'une variable aléatoire distribuée selon la loi de Poisson coïncident et sont égales au paramètre de cette loi, c'est-à-dire
Preuve.
Exemple. Pour promouvoir ses produits sur le marché, l'entreprise place des dépliants dans les boîtes aux lettres. L'expérience montre que dans environ un cas sur 2 000, une ordonnance suit. Trouvez la probabilité qu'en plaçant 10 000 annonces, au moins une commande arrive, le nombre moyen de commandes reçues et la variance du nombre de commandes reçues.
Solution. Ici
Nous trouverons la probabilité qu'au moins un ordre arrive grâce à la probabilité de l'événement opposé, c'est-à-dire
Flux aléatoire d'événements. Un flux d’événements est une séquence d’événements qui se produisent à des moments aléatoires. Des exemples typiques de flux sont les pannes des réseaux informatiques, les appels aux centraux téléphoniques, un flux de demandes de réparation d'équipements, etc.
Couler les événements sont appelés Stationnaire, si la probabilité qu'un nombre particulier d'événements tombe dans un intervalle de temps de longueur dépend uniquement de la longueur de l'intervalle et ne dépend pas de l'emplacement de l'intervalle de temps sur l'axe du temps.
La condition de stationnarité est satisfaite par le flux de requêtes dont les caractéristiques probabilistes ne dépendent pas du temps. En particulier, un flux stationnaire se caractérise par une densité constante (le nombre moyen de requêtes par unité de temps). Dans la pratique, il existe souvent des flux de demandes qui (au moins pour une période limitée) peuvent être considérés comme stationnaires. Par exemple, le flux d'appels sur un central téléphonique urbain dans une période de 12 à 13 heures peut être considéré comme un appel fixe. Le même flux au cours d’une journée entière ne peut plus être considéré comme stationnaire (la nuit, la densité d’appels est nettement inférieure à celle du jour).
Couler les événements sont appelés un flux sans séquelle, si pour des périodes ne se chevauchant pas, le nombre d'événements tombant sur l'une d'elles ne dépend pas du nombre d'événements tombant sur les autres.
La condition d’absence de séquelle – la plus essentielle pour le flux le plus simple – fait que les applications entrent dans le système indépendamment les unes des autres. Par exemple, un flux de passagers entrant dans une station de métro peut être considéré comme un flux sans séquelles car les raisons qui ont déterminé l'arrivée d'un passager individuel à un moment donné et non à un autre ne sont, en règle générale, pas liées aux raisons similaires d'autres passagers. . Cependant, la condition d’absence de séquelles peut être facilement violée en raison de l’apparition d’une telle dépendance. Par exemple, le flux de passagers sortant d’une station de métro ne peut plus être considéré comme un flux sans séquelle, puisque les instants de sortie des passagers arrivant dans un même train sont dépendants les uns des autres.
Couler les événements sont appelés ordinaire, si la probabilité que deux événements ou plus se produisent dans un court intervalle de temps t est négligeable par rapport à la probabilité qu'un événement se produise (à cet égard, la loi de Poisson est appelée loi des événements rares).
La condition d'ordinaire signifie que les commandes arrivent individuellement, et non par paires, triplets, etc. écart de variance Distribution de Bernoulli
Par exemple, le flux de clients entrant dans un salon de coiffure peut être considéré comme presque ordinaire. Si, dans un flux extraordinaire, les candidatures n'arrivent que par paires, seulement par triplets, etc., alors le flux extraordinaire peut facilement être réduit à un flux ordinaire ; Pour ce faire, il suffit de considérer un flux de paires, de triplés, etc. au lieu d'un flux de demandes individuelles. Ce sera plus difficile si chaque demande peut s'avérer aléatoirement double, triple, etc. traiter un flux d’événements non homogènes, mais hétérogènes.
Si un flux d’événements possède les trois propriétés (c’est-à-dire stationnaire, ordinaire et sans séquelle), alors il est appelé flux de Poisson simple (ou stationnaire). Le nom "Poisson" est dû au fait que si les conditions énumérées sont remplies, le nombre d'événements tombant sur un intervalle de temps fixe sera réparti sur loi de Poisson
Voici le nombre moyen d'événements UN, apparaissant par unité de temps.
Cette loi est à un paramètre, c'est-à-dire pour le régler, il vous suffit de connaître un paramètre. On peut montrer que l'espérance et la variance dans la loi de Poisson sont numériquement égales :
Exemple. Disons qu'au milieu d'une journée de travail, le nombre moyen de requêtes est de 2 par seconde. Quelle est la probabilité que 1) aucune candidature ne soit reçue en une seconde, 2) 10 candidatures arrivent en deux secondes ?
Solution. Puisque la validité de l’application de la loi de Poisson ne fait aucun doute et que son paramètre est donné (= 2), la solution du problème se réduit à l’application de la formule de Poisson (19.11)
1) t = 1, m = 0:
2) t = 2, m = 10:
Loi des grands nombres. La base mathématique du fait que les valeurs d'une variable aléatoire se regroupent autour de certaines valeurs constantes est la loi des grands nombres.
Historiquement, la première formulation de la loi des grands nombres fut le théorème de Bernoulli :
« Avec une augmentation illimitée du nombre d'expériences identiques et indépendantes n, la fréquence d'apparition de l'événement A converge en probabilité vers sa probabilité », c'est-à-dire
où est la fréquence d'apparition de l'événement A dans n expériences,
Essentiellement, l'expression (19.10) signifie qu'avec un grand nombre d'expériences, la fréquence d'apparition de l'événement UN peut remplacer la probabilité inconnue de cet événement, et plus le nombre d'expériences réalisées est grand, plus p* est proche de p. Un fait historique intéressant. K. Pearson a lancé une pièce de monnaie 12 000 fois et ses armoiries sont apparues 6 019 fois (fréquence 0,5016). En lançant la même pièce 24 000 fois, il obtenait 12 012 blasons, soit fréquence 0,5005.
La forme la plus importante de la loi des grands nombres est le théorème de Chebyshev : avec une augmentation illimitée du nombre d'expériences indépendantes à variance finie et réalisées dans des conditions identiques, la moyenne arithmétique des valeurs observées de la variable aléatoire converge en probabilité vers son espérance mathématique. Sous forme analytique, ce théorème peut s'écrire comme suit :
En plus de sa signification théorique fondamentale, le théorème de Chebyshev a également d'importantes applications pratiques, par exemple dans la théorie de la mesure. Après avoir pris n mesures d'une certaine quantité X, obtenez différentes valeurs non correspondantes X 1, X 2, ..., xn. Pour la valeur approximative de la grandeur mesurée X prendre la moyenne arithmétique des valeurs observées
Où, Plus nous effectuons d’expériences, plus le résultat sera précis. Le fait est que la dispersion de la quantité diminue avec l'augmentation du nombre d'expériences réalisées, car
D(X 1) = D(X 2)=…= D(xn) D(X) , Que
La relation (19.13) montre que même avec une grande imprécision des instruments de mesure (grande valeur), en augmentant le nombre de mesures, il est possible d'obtenir un résultat avec une précision arbitrairement élevée.
À l'aide de la formule (19.10), vous pouvez trouver la probabilité que la fréquence statistique ne s'écarte pas de la probabilité de plus de


Exemple. La probabilité d'un événement dans chaque essai est de 0,4. Combien de tests faut-il effectuer pour s'attendre, avec une probabilité d'au moins 0,8, à ce que la fréquence relative d'un événement s'écarte de la probabilité en valeur absolue de moins de 0,01 ?
Solution. D'après la formule (19.14)


par conséquent, selon le tableau, il y a deux applications
ainsi, n 3932.
Plage de variation (ou plage de variation) - c'est la différence entre les valeurs maximales et minimales de la caractéristique :
Dans notre exemple, la plage de variation du rendement des équipes est la suivante : dans la première brigade R = 105-95 = 10 enfants, dans la deuxième brigade R = 125-75 = 50 enfants. (5 fois plus). Cela suggère que la production de la 1ère brigade est plus « stable », mais que la deuxième brigade dispose de plus de réserves pour augmenter la production, car Si tous les ouvriers atteignent le rendement maximum pour cette brigade, elle pourra produire 3 * 125 = 375 pièces, et dans la 1ère brigade seulement 105 * 3 = 315 pièces.
Si les valeurs extrêmes d'une caractéristique ne sont pas typiques de la population, des plages de quartiles ou de déciles sont utilisées. La plage quartile RQ= Q3-Q1 couvre 50 % du volume de la population, la plage du premier décile RD1 = D9-D1 couvre 80 % des données, la plage du deuxième décile RD2= D8-D2 – 60 %.
L'inconvénient de l'indicateur de plage de variation est que sa valeur ne reflète pas toutes les fluctuations du trait.
L'indicateur général le plus simple reflétant toutes les fluctuations d'une caractéristique est écart linéaire moyen, qui est la moyenne arithmétique des écarts absolus des options individuelles par rapport à leur valeur moyenne :
,
pour les données groupées ![]() ,
,
où xi est la valeur de l'attribut dans une série discrète ou le milieu de l'intervalle dans la distribution d'intervalle.
Dans les formules ci-dessus, les différences au numérateur sont prises modulo, sinon, selon la propriété de la moyenne arithmétique, le numérateur sera toujours égal à zéro. Par conséquent, l'écart linéaire moyen est rarement utilisé dans la pratique statistique, uniquement dans les cas où la somme des indicateurs sans prendre en compte le signe a un sens économique. Avec son aide, par exemple, la composition de la main-d'œuvre, la rentabilité de la production et le chiffre d'affaires du commerce extérieur sont analysés.
Variation des traits est le carré moyen des écarts par rapport à leur valeur moyenne :
écart simple ![]() ,
,
variance pondérée  .
.
La formule de calcul de l'écart peut être simplifiée :
Ainsi, la variance est égale à la différence entre la moyenne des carrés de l'option et le carré de la moyenne de l'option population :  .
.
Cependant, en raison de la somme des écarts au carré, la variance donne une idée déformée des écarts, c'est pourquoi la moyenne est calculée sur cette base. écart-type, qui montre à quel point en moyenne les variantes spécifiques d'un trait s'écartent de leur valeur moyenne. Calculé en prenant la racine carrée de la variance :
pour les données non groupées  ,
,
pour séries de variations 
Plus la valeur de la variance et de l'écart type est petite, plus la population est homogène, plus la valeur moyenne sera fiable (typique).
La moyenne linéaire et l'écart type sont nommés nombres, c'est-à-dire qu'ils sont exprimés en unités de mesure d'une caractéristique, sont identiques dans leur contenu et proches dans leur signification.
Il est recommandé de calculer les variations absolues à l'aide de tableaux.
Tableau 3 - Calcul des caractéristiques de variation (en utilisant l'exemple de la période de données sur le rendement posté des travailleurs d'équipage)
Nombre de travailleurs |
Le milieu de l'intervalle |
Valeurs calculées |
|||||
Total: |
|||||||
Rendement moyen des travailleurs par quart de travail : ![]()
Déviation linéaire moyenne : ![]()
Écart de production : 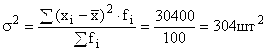
L'écart type de la production des travailleurs individuels par rapport à la production moyenne :
.
1 Calcul de la dispersion par la méthode des moments
Le calcul des variances implique des calculs fastidieux (surtout si la moyenne est exprimée sous la forme d'un grand nombre avec plusieurs décimales). Les calculs peuvent être simplifiés en utilisant une formule simplifiée et des propriétés de dispersion.
La dispersion a les propriétés suivantes :
- Si toutes les valeurs d'une caractéristique sont réduites ou augmentées de la même valeur A, alors la dispersion ne diminuera pas :
 ,
,
 , alors ou
, alors ou 
En utilisant les propriétés de dispersion et en réduisant d'abord toutes les variantes de la population par la valeur A, puis en divisant par la valeur de l'intervalle h, nous obtenons une formule pour calculer la dispersion dans des séries de variations à intervalles égaux manière de moments : ,
,
où est la dispersion calculée selon la méthode des moments ;
h – valeur de l'intervalle de la série de variations ;
– option de nouvelles valeurs (transformées) ;
A est une valeur constante, qui est utilisée comme milieu de l'intervalle avec la fréquence la plus élevée ; ou l'option avec la fréquence la plus élevée ;  – carré du moment du premier ordre ;
– carré du moment du premier ordre ;
– moment du second ordre.
Calculons la dispersion en utilisant la méthode des moments basée sur les données sur le rendement des équipes des travailleurs de l’équipe.
Tableau 4 - Calcul de la variance par la méthode des moments
Groupes d'ouvriers de production, pcs. |
Nombre de travailleurs |
Le milieu de l'intervalle |
Valeurs calculées |
||
Procédure de calcul :


- On calcule la variance :
2 Calcul de la variance d'une caractéristique alternative
Parmi les caractéristiques étudiées par les statistiques, il y a aussi celles qui n'ont que deux significations mutuellement exclusives. Ce sont des signes alternatifs. On leur attribue respectivement deux valeurs quantitatives : les options 1 et 0. La fréquence de l'option 1, notée p, est la proportion d'unités possédant cette caractéristique. La différence 1-р=q est la fréquence des options 0. Ainsi,
xi |
|
Moyenne arithmétique du signe alternatif ![]() , car p+q=1.
, car p+q=1.
Variance des traits alternatifs
, parce que 1-р=q
Ainsi, la variance d’une caractéristique alternative est égale au produit de la proportion d’unités possédant cette caractéristique et de la proportion d’unités ne possédant pas cette caractéristique.
Si les valeurs 1 et 0 apparaissent aussi souvent, c'est-à-dire p=q, la variance atteint son maximum pq=0,25.
La variance d'un attribut alternatif est utilisée dans les enquêtes par sondage, par exemple sur la qualité des produits.
3 Variance entre les groupes. Règle d'ajout d'écart
La dispersion, contrairement aux autres caractéristiques de variation, est une quantité additive. C'est-à-dire dans l'ensemble, qui est divisé en groupes selon les caractéristiques des facteurs X , variance de la caractéristique résultante oui peut être décomposé en variance au sein de chaque groupe (au sein des groupes) et en variance entre groupes (entre groupes). Ensuite, en plus d’étudier la variation d’un trait dans l’ensemble de la population, il devient possible d’étudier la variation dans chaque groupe, ainsi qu’entre ces groupes.
Écart total mesure la variation d'un trait à dans son intégralité sous l'influence de tous les facteurs qui ont provoqué cette variation (écarts). Il est égal à l'écart carré moyen des valeurs individuelles de l'attribut à de la moyenne générale et peut être calculé comme une variance simple ou pondérée.
Variance intergroupe caractérise la variation du trait résultant à causé par l'influence du facteur-signe X, qui constituait la base du regroupement. Il caractérise la variation des moyennes de groupe et est égal au carré moyen des écarts des moyennes de groupe par rapport à la moyenne globale :  ,
,
où est la moyenne arithmétique du i-ème groupe ;
– nombre d'unités dans le i-ème groupe (fréquence du i-ème groupe) ;
– la moyenne globale de la population.
Variation au sein du groupe reflète la variation aléatoire, c'est-à-dire la partie de la variation qui est causée par l'influence de facteurs non pris en compte et ne dépend pas de l'attribut facteur qui constitue la base du regroupement. Il caractérise la variation des valeurs individuelles par rapport aux moyennes de groupe et est égal à l'écart carré moyen des valeurs individuelles de l'attribut à au sein d'un groupe à partir de la moyenne arithmétique de ce groupe (moyenne du groupe) et est calculée comme une variance simple ou pondérée pour chaque groupe : ![]() ou
ou ![]() ,
,
où est le nombre d'unités dans le groupe.
Sur la base des variances intra-groupe pour chaque groupe, on peut déterminer moyenne globale des variances au sein du groupe:
.
La relation entre les trois dispersions est appelée règles d'ajout d'écarts, selon lequel la variance totale est égale à la somme de la variance inter-groupe et de la moyenne des variances intra-groupe :
Exemple. En étudiant l'influence de la catégorie tarifaire (qualification) des travailleurs sur le niveau de productivité de leur travail, les données suivantes ont été obtenues.
Tableau 5 – Répartition des travailleurs selon la production horaire moyenne.
№ p/p |
Travailleurs de la 4ème catégorie |
Travailleurs de la 5ème catégorie |
|||||
Sortir |
Sortir |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
Dans cet exemple, les travailleurs sont divisés en deux groupes selon les caractéristiques des facteurs X– les qualifications, qui se caractérisent par leur rang. Le trait qui en résulte – la production – varie à la fois sous son influence (variation intergroupe) et en raison d'autres facteurs aléatoires (variation intragroupe). L'objectif est de mesurer ces variations à l'aide de trois variances : totale, inter-groupes et intra-groupes. Le coefficient de détermination empirique montre la proportion de variation dans la caractéristique résultante à sous l'influence d'un signe facteur X. Reste de la variation totale à causée par des changements dans d’autres facteurs.
Dans l’exemple, le coefficient de détermination empirique est : ![]() soit 66,7%,
soit 66,7%,
Cela signifie que 66,7 % de la variation de la productivité des travailleurs est due à des différences de qualifications, et 33,3 % est due à l'influence d'autres facteurs.
Relation de corrélation empirique montre le lien étroit entre le regroupement et les caractéristiques de performance. Calculé comme la racine carrée du coefficient de détermination empirique :
Le rapport de corrélation empirique, comme , peut prendre des valeurs de 0 à 1.
S'il n'y a pas de connexion, alors =0. Dans ce cas =0, c'est-à-dire que les moyennes des groupes sont égales les unes aux autres et qu'il n'y a pas de variation intergroupe. Cela signifie que le facteur caractéristique de regroupement n'affecte pas la formation d'une variation générale.
Si la connexion est fonctionnelle, alors =1. Dans ce cas, la variance des moyennes du groupe est égale à la variance totale (), c'est-à-dire qu'il n'y a pas de variation au sein du groupe. Cela signifie que la caractéristique de regroupement détermine entièrement la variation de la caractéristique résultante étudiée.
Plus la valeur du rapport de corrélation est proche de l'unité, plus le lien entre les caractéristiques est proche de la dépendance fonctionnelle.
Pour évaluer qualitativement l’étroitesse des liens entre les caractéristiques, les relations de Chaddock sont utilisées.
Dans l'exemple ![]() , ce qui indique un lien étroit entre la productivité des travailleurs et leurs qualifications.
, ce qui indique un lien étroit entre la productivité des travailleurs et leurs qualifications.
En plus d'étudier la variation d'une caractéristique dans l'ensemble de la population, il est souvent nécessaire de retracer les changements quantitatifs de la caractéristique à travers les groupes dans lesquels la population est divisée, ainsi qu'entre les groupes. Cette étude de la variation est réalisée en calculant et en analysant différents types de variance.
Il existe des écarts totaux, intergroupes et intragroupes.
Variance totale σ 2 mesure la variation d'un trait dans l'ensemble de la population sous l'influence de tous les facteurs qui ont provoqué cette variation.
La variance intergroupe (δ) caractérise la variation systématique, c'est-à-dire différences dans la valeur du trait étudié qui surviennent sous l'influence du trait facteur qui constitue la base du groupe. Il est calculé à l'aide de la formule : 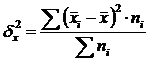 .
.
Variance intra-groupe (σ) reflète une variation aléatoire, c'est-à-dire une partie de la variation qui se produit sous l'influence de facteurs non pris en compte et ne dépend pas du facteur-attribut qui constitue la base du groupe. Il est calculé par la formule : 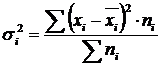 .
.
Moyenne des écarts intra-groupe:  .
.
Il existe une loi reliant 3 types de dispersion. La variance totale est égale à la somme de la moyenne des variances intra-groupe et inter-groupe : ![]() .
.
Ce rapport est appelé règle d'ajout d'écarts.
Un indicateur largement utilisé en analyse est la proportion de variance entre les groupes dans la variance totale. C'est appelé coefficient de détermination empirique (η 2) : .
La racine carrée du coefficient de détermination empirique s'appelle rapport de corrélation empirique (η):
 .
.
Il caractérise l'influence de la caractéristique qui constitue la base du groupe sur la variation de la caractéristique résultante. Le rapport de corrélation empirique varie de 0 à 1.
Démontrons son utilisation pratique à l'aide de l'exemple suivant (tableau 1).
Exemple n°1. Tableau 1 - Productivité du travail de deux groupes de travailleurs dans l'un des ateliers de l'OBNL "Cyclone"
Calculons les moyennes et variances globales et de groupe :
Les données initiales permettant de calculer la moyenne de la variance intragroupe et intergroupe sont présentées dans le tableau. 2.
Tableau 2
Calcul et δ 2 pour deux groupes de travailleurs.
|
Groupes de travailleurs | Nombre de travailleurs, de personnes | Moyenne, enfants/équipe | Dispersion |
| Formation technique complétée | 5 | 95 | 42,0 |
| Ceux qui n’ont pas suivi de formation technique | 5 | 81 | 231,2 |
| Tous les travailleurs | 10 | 88 | 185,6 |
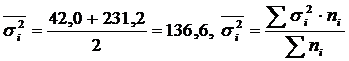 .
.
Variance intergroupe
Écart total :
Ainsi, le rapport de corrélation empirique : .
Parallèlement à la variation des caractéristiques quantitatives, une variation des caractéristiques qualitatives peut également être observée. Cette étude de variation est réalisée en calculant les types de variances suivants :
La dispersion intra-groupe de la part est déterminée par la formule
Où n je– nombre d'unités dans des groupes séparés.La part de la caractéristique étudiée dans l'ensemble de la population, qui est déterminée par la formule :
Les trois types de variance sont liés les uns aux autres comme suit :
Cette relation de variances est appelée théorème d'addition des variances de la part des traits.