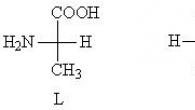
.
.
Naopak, ak je nezáporné a.e. fungovať tak, že  , potom existuje absolútne spojitá miera pravdepodobnosti na takej, že je to jej hustota.
, potom existuje absolútne spojitá miera pravdepodobnosti na takej, že je to jej hustota.
Nahradenie miery v Lebesgueovom integráli:
 ,
,
kde je akákoľvek Borelova funkcia, ktorá je integrovateľná vzhľadom na mieru pravdepodobnosti.
Disperzia, druhy a vlastnosti disperzie Pojem disperzia
Rozptyl v štatistike sa zistí ako štandardná odchýlka jednotlivých hodnôt charakteristiky na druhú od aritmetického priemeru. V závislosti od počiatočných údajov sa určuje pomocou jednoduchých a vážených vzorcov rozptylu:
1. Jednoduchá variácia(pre nezoskupené údaje) sa vypočíta pomocou vzorca:
![]()
2. Vážená odchýlka (pre série variácií):

kde n je frekvencia (opakovateľnosť faktora X)
Príklad hľadania rozptylu
Táto stránka popisuje štandardný príklad hľadania odchýlky, môžete sa pozrieť aj na iné problémy na jej nájdenie
Príklad 1. Určenie skupinového, skupinového priemeru, medziskupinového a celkového rozptylu
Príklad 2. Nájdenie rozptylu a variačného koeficientu v tabuľke zoskupení
Príklad 3. Nájdenie rozptylu v diskrétnom rade
Príklad 4. Nasledujúce údaje sú dostupné pre skupinu 20 korešpondenčných študentov. Je potrebné zostrojiť intervalový rad rozdelenia charakteristiky, vypočítať priemernú hodnotu charakteristiky a preštudovať jej rozptyl

Zostavme intervalové zoskupenie. Určme rozsah intervalu pomocou vzorca:
![]()
kde X max je maximálna hodnota charakteristiky zoskupenia; X min – minimálna hodnota zoskupovacej charakteristiky; n – počet intervalov:
Akceptujeme n=5. Krok je: h = (192 - 159)/5 = 6,6
Vytvorme intervalové zoskupenie

Pre ďalšie výpočty vytvoríme pomocnú tabuľku:

X"i – stred intervalu. (napríklad stred intervalu 159 – 165,6 = 162,3)
Priemernú výšku študentov určíme pomocou vzorca váženého aritmetického priemeru:

Stanovme rozptyl pomocou vzorca:
Vzorec je možné transformovať takto:

Z tohto vzorca to vyplýva rozptyl sa rovná rozdiel medzi priemerom druhých mocnín možností a druhou mocninou a priemerom.
Rozptyl vo variačných sériách s rovnakými intervalmi pomocou metódy momentov možno vypočítať nasledujúcim spôsobom pomocou druhej vlastnosti disperzie (vydelením všetkých možností hodnotou intervalu). Určenie rozptylu, vypočítané pomocou metódy momentov, pomocou nasledujúceho vzorca je menej prácne:

kde i je hodnota intervalu; A je konvenčná nula, pre ktorú je vhodné použiť stred intervalu s najvyššou frekvenciou; m1 je druhá mocnina momentu prvého rádu; m2 - moment druhého rádu
Alternatívny rozptyl vlastností (ak sa v štatistickej populácii charakteristika zmení tak, že existujú iba dve vzájomne sa vylučujúce možnosti, potom sa takáto variabilita nazýva alternatívna) možno vypočítať pomocou vzorca:

Dosadením q = 1- p do tohto disperzného vzorca dostaneme:

Typy rozptylu
Celkový rozptyl meria variácie charakteristiky v celej populácii ako celku pod vplyvom všetkých faktorov, ktoré spôsobujú túto variáciu. Rovná sa strednej štvorci odchýlok jednotlivých hodnôt charakteristiky x od celkovej strednej hodnoty x a možno ju definovať ako jednoduchý rozptyl alebo vážený rozptyl.
Rozptyl v rámci skupiny charakterizuje náhodnú variáciu, t.j. časť variácie, ktorá je spôsobená vplyvom nezapočítaných faktorov a nezávisí od atribútu faktora, ktorý tvorí základ skupiny. Takáto disperzia sa rovná strednej štvorci odchýlok jednotlivých hodnôt atribútu v rámci skupiny X od aritmetického priemeru skupiny a možno ju vypočítať ako jednoduchú disperziu alebo ako váženú disperziu.
teda merania rozptylu v rámci skupiny variácia vlastnosti v rámci skupiny a je určená vzorcom:

kde xi je priemer skupiny; ni je počet jednotiek v skupine.
Napríklad vnútroskupinové odchýlky, ktoré je potrebné určiť pri úlohe študovať vplyv kvalifikácie pracovníkov na úroveň produktivity práce v dielni, vykazujú odchýlky vo výstupe v každej skupine spôsobené všetkými možnými faktormi (technický stav zariadení, dostupnosť nástroje a materiály, vek pracovníkov, pracovná náročnosť atď.), okrem rozdielov v kvalifikačnej kategórii (v rámci skupiny majú všetci pracovníci rovnakú kvalifikáciu).
Priemer odchýlok v rámci skupiny odráža náhodnú variáciu, to znamená tú časť variácie, ktorá sa vyskytla pod vplyvom všetkých ostatných faktorov, s výnimkou faktora zoskupovania. Vypočíta sa pomocou vzorca:

Medziskupinový rozptyl charakterizuje systematickú variáciu výslednej charakteristiky, ktorá je spôsobená vplyvom faktora-atribútu, ktorý tvorí základ skupiny. Rovná sa strednej štvorci odchýlok skupinových priemerov od celkového priemeru. Medziskupinový rozptyl sa vypočíta podľa vzorca:

Hlavnými zovšeobecňujúcimi ukazovateľmi variácií v štatistike sú rozptyly a štandardné odchýlky.
Disperzia toto aritmetický priemer štvorcové odchýlky každej charakteristickej hodnoty od celkového priemeru. Rozptyl sa zvyčajne nazýva stredný štvorec odchýlok a označuje sa 2. V závislosti od zdrojových údajov možno rozptyl vypočítať pomocou jednoduchého alebo váženého aritmetického priemeru:
nevážený (jednoduchý) rozptyl;
 vážený rozptyl.
vážený rozptyl.
Smerodajná odchýlka ide o zovšeobecňujúcu charakteristiku absolútnych veľkostí variácie znaky v súhrne. Vyjadruje sa v rovnakých merných jednotkách ako atribút (v metroch, tonách, percentách, hektároch atď.).
Smerodajná odchýlka je druhá odmocnina rozptylu a označuje sa :
 štandardná odchýlka nevážená;
štandardná odchýlka nevážená;
 vážená štandardná odchýlka.
vážená štandardná odchýlka.
Smerodajná odchýlka je mierou spoľahlivosti priemeru. Čím menšia je štandardná odchýlka, tým lepšie aritmetický priemer odráža celú reprezentovanú populáciu.
Výpočtu smerodajnej odchýlky predchádza výpočet rozptylu.
Postup výpočtu váženého rozptylu je nasledujúci:
1) určte vážený aritmetický priemer:
2) vypočítajte odchýlky možností od priemeru:
3) druhá mocnina odchýlky každej možnosti od priemeru:
4) vynásobte druhé mocniny odchýlok váhami (frekvenciami):
5) zhrňte výsledné produkty:
![]()
6) výsledná suma sa vydelí súčtom váh:

Príklad 2.1

Vypočítajme vážený aritmetický priemer:

Hodnoty odchýlok od priemeru a ich štvorcov sú uvedené v tabuľke. Definujme rozptyl:

Štandardná odchýlka sa bude rovnať:

Ak sú zdrojové údaje prezentované vo forme intervalu distribučná séria , potom musíte najprv určiť diskrétnu hodnotu atribútu a potom použiť opísanú metódu.
Príklad 2.2
Ukážme výpočet rozptylu pre intervalový rad s použitím údajov o rozdelení osiatej plochy JZD podľa výnosu pšenice.

Aritmetický priemer je:

Vypočítajme rozptyl:

6.3. Výpočet rozptylu pomocou vzorca na základe individuálnych údajov
Technika výpočtu odchýlky zložité a s veľkými hodnotami možností a frekvencií môže byť ťažkopádne. Výpočty je možné zjednodušiť pomocou vlastností disperzie.
Disperzia má nasledujúce vlastnosti.
1. Zníženie alebo zvýšenie hmotností (frekvencií) meniacej sa charakteristiky o určitý počet krát nemení rozptyl.
2. Znížte alebo zvýšte každú hodnotu charakteristiky o rovnakú konštantnú hodnotu A nemení rozptyl.
3. Znížte alebo zvýšte každú hodnotu charakteristiky o určitý počet krát k respektíve znižuje alebo zvyšuje rozptyl v k 2 krát smerodajná odchýlka v k raz.
4. Rozptyl charakteristiky vzhľadom na ľubovoľnú hodnotu je vždy väčší ako rozptyl vzhľadom na aritmetický priemer na štvorec rozdielu medzi priemernými a ľubovoľnými hodnotami:
![]()
Ak A 0, potom dospejeme k nasledujúcej rovnosti:
to znamená, že rozptyl charakteristiky sa rovná rozdielu medzi strednou druhou mocninou charakteristických hodnôt a druhou mocninou priemeru.
Každá vlastnosť môže byť použitá samostatne alebo v kombinácii s inými pri výpočte rozptylu.
Postup výpočtu rozptylu je jednoduchý:
1) určiť aritmetický priemer :
2) odmocnina aritmetického priemeru:

3) druhá mocnina odchýlky každého variantu série:
X i 2 .
4) nájdite súčet druhých mocnín možností:
5) vydeľte súčet štvorcov možností ich počtom, t. j. určte priemerný štvorec:
6) určte rozdiel medzi strednou druhou mocninou charakteristiky a druhou mocninou priemeru:
Príklad 3.1 K dispozícii sú nasledujúce údaje o produktivite pracovníkov:

Urobme nasledujúce výpočty:
![]()
Riešenie.
Ako mieru rozptylu hodnôt náhodných premenných používame disperzia
Disperzia (slovo disperzia znamená „rozptyl“) je miera rozptylu hodnôt náhodných premenných vzhľadom na jeho matematické očakávania. Disperzia je matematické očakávanie druhej mocniny odchýlky náhodnej premennej od jej matematického očakávania
Ak je náhodná premenná diskrétna s nekonečnou, ale spočítateľnou množinou hodnôt, potom
ak rad na pravej strane rovnosti konverguje.
Vlastnosti disperzie.
- 1. Rozptyl konštantnej hodnoty je nulový
- 2. Rozptyl súčtu náhodných premenných sa rovná súčtu rozptylov
- 3. Konštantný faktor možno odobrať zo znamienka druhej mocniny disperzie
Rozptyl rozdielu náhodných premenných sa rovná súčtu rozptylov
Táto vlastnosť je dôsledkom druhej a tretej vlastnosti. Rozdiely sa môžu len sčítať.
Je vhodné vypočítať disperziu pomocou vzorca, ktorý možno ľahko získať pomocou vlastností disperzie
Rozptyl je vždy pozitívny.
Rozptyl má rozmerštvorcový rozmer samotnej náhodnej premennej, čo nie je vždy vhodné. Preto množstvo
Smerodajná odchýlka(štandardná odchýlka alebo štandard) náhodnej premennej je aritmetická hodnota druhej odmocniny jej rozptylu
Hoďte dve mince v nominálnych hodnotách 2 a 5 rubľov. Ak minca pristane ako erb, pridelí sa nula bodov a ak pristane ako číslo, potom počet bodov, ktorý sa rovná nominálnej hodnote mince. Nájdite matematické očakávanie a rozptyl počtu bodov.
Riešenie. Najprv nájdime rozdelenie náhodnej premennej X - počet bodov. Všetky kombinácie - (2;5),(2;0),(0;5),(0;0) - sú rovnako pravdepodobné a distribučný zákon je:

Očakávaná hodnota:
Pomocou vzorca nájdeme rozptyl
prečo počítame
Príklad 2
Nájdite neznámu pravdepodobnosť R, matematické očakávanie a rozptyl diskrétnej náhodnej premennej špecifikovanej tabuľkou rozdelenia pravdepodobnosti
Nájdeme matematické očakávanie a rozptyl:
M(X) = 00,0081 + 10,0756 + 20,2646 + 3 0,4116 + +40,2401=2,8
Na výpočet disperzie použijeme vzorec (19.4)
D(X) = 020 ,0081 + 120,0756 + 220,2646 + 320,4116 + 420,2401 - 2,82 = 8,68 -

Príklad 3 Dvaja rovnako silní športovci organizujú turnaj, ktorý trvá buď do prvého víťazstva jedného z nich, alebo do odohrania piatich zápasov. Pravdepodobnosť výhry jednej hry pre každého zo športovcov je 0,3 a pravdepodobnosť remízy 0,4. Nájdite distribučný zákon, matematické očakávanie a rozptyl počtu odohraných hier.
Riešenie. Náhodná hodnota X- počet odohraných hier, nadobúda hodnoty od 1 do 5, t.j.
Stanovme si pravdepodobnosti ukončenia zápasu. Zápas sa skončí v prvom sete, ak jeden z ich športovcov vyhrá. Pravdepodobnosť výhry je
R(1) = 0,3+0,3 =0,6.
Ak bola remíza (pravdepodobnosť remízy je 1 - 0,6 = 0,4), zápas pokračuje. Zápas sa skončí v druhej hre, ak bola prvá remíza a niekto vyhral druhú. Pravdepodobnosť
R(2) = 0,4 0,6=0,24.
Rovnako tak sa zápas skončí treťou partiou, ak boli dve remízy za sebou a opäť niekto vyhral
R(3) = 0,4 0,4 0,6 = 0,096. R(4)= 0,4 0,4 0,4 0,6=0,0384.
Piata hra je posledná v akejkoľvek verzii.
R(5)= 1 - (R(1)+R(2)+R(3)+R(4)) = 0,0256.
Dajme si všetko do tabuľky. Distribučný zákon náhodnej premennej „počet vyhraných hier“ má tvar
Očakávaná hodnota
Rozptyl vypočítame pomocou vzorca (19.4)
Štandardné diskrétne distribúcie.
Binomické rozdelenie. Nechajte implementovať Bernoulliho experimentálnu schému: n identické nezávislé experimenty, v každom z nich event A sa môže objaviť s konštantnou pravdepodobnosťou p a neobjaví sa s pravdepodobnosťou
(pozri prednášku 18).
Počet výskytov udalosti A v týchto n experimentoch existuje diskrétna náhodná premenná X, ktorého možné hodnoty sú:
0; 1; 2; ... ;m; ... ; n.
Pravdepodobnosť výskytu m udalosti A v špecifickej sérii n experimenty s a distribučný zákon takejto náhodnej veličiny je daný Bernoulliho vzorcom (pozri prednášku 18)
 |



Číselné charakteristiky náhodnej premennej X rozdelené podľa binomického zákona:

Ak n je skvelé (), potom, keď, vzorec (19.6) prechádza do vzorca
a tabuľková Gaussova funkcia (tabuľka hodnôt Gaussovej funkcie je uvedená na konci prednášky 18).
V praxi často nie je dôležitá samotná pravdepodobnosť výskytu. m diania A v konkrétnej sérii od n experimenty a pravdepodobnosť, že udalosť A sa objaví o nič menej
krát a nie viac ako krát, t.j. pravdepodobnosť, že X nadobudne hodnoty
Aby sme to dosiahli, musíme zhrnúť pravdepodobnosti
Ak n je skvelé (), potom, keď sa vzorec (19.9) zmení na približný vzorec

tabuľková funkcia. Tabuľky sú uvedené na konci prednášky 18.
Pri používaní tabuliek je potrebné počítať s tým
Príklad 1. Auto, ktoré sa blíži ku križovatke, môže pokračovať v pohybe po ktorejkoľvek z troch ciest: A, B alebo C s rovnakou pravdepodobnosťou. Ku križovatke sa blíži päť áut. Nájdite priemerný počet áut, ktoré pôjdu po ceste A, a pravdepodobnosť, že po ceste B pôjdu tri autá.
Riešenie. Počet áut prechádzajúcich po každej ceste je náhodná veličina. Ak predpokladáme, že všetky autá blížiace sa ku križovatke idú nezávisle od seba, potom je táto náhodná veličina rozdelená podľa binomického zákona s
n= 5 a p = .
Preto je priemerný počet áut, ktoré pôjdu po ceste A, podľa vzorca (19.7)
a požadovaná pravdepodobnosť pri
Príklad 2 Pravdepodobnosť zlyhania zariadenia počas každého testu je 0,1. Vykonáva sa 60 testov zariadenia. Aká je pravdepodobnosť, že dôjde k poruche zariadenia: a) 15-krát; b) nie viac ako 15-krát?
A. Keďže počet testov je 60, použijeme vzorec (19.8)
Podľa tabuľky 1 prílohy k prednáške 18 nachádzame
b. Používame vzorec (19.10).
Podľa tabuľky 2 prílohy k prednáške 18
- - 0,495
- 0,49995
Poissonovo rozdelenie) zákon zriedkavých udalostí). Ak n veľké a R málo () a produkt atď si zachováva konštantnú hodnotu, ktorú označíme l,
potom sa vzorec (19.6) stane Poissonovým vzorcom

Poissonov zákon o rozdelení má tvar:

Je zrejmé, že definícia Poissonovho zákona je správna, pretože hlavná vlastnosť distribučnej série
Hotovo, pretože súčet série
Sériové rozšírenie funkcie at
Veta. Matematické očakávanie a rozptyl náhodnej premennej rozloženej podľa Poissonovho zákona sa zhodujú a rovnajú sa parametru tohto zákona, t.j.
Dôkaz.
Príklad. Na propagáciu svojich produktov na trhu spoločnosť umiestňuje letáky do poštových schránok. Doterajšie skúsenosti ukazujú, že približne v jednom prípade z 2000 nasleduje objednávka. Zistite pravdepodobnosť, že pri zadaní 10 000 inzerátov príde aspoň jedna objednávka, priemerný počet prijatých objednávok a rozptyl počtu prijatých objednávok.
Riešenie. Tu
Pravdepodobnosť, že príde aspoň jedna objednávka, nájdeme cez pravdepodobnosť opačnej udalosti, t.j.
Náhodný tok udalostí. Prúd udalostí je sled udalostí, ktoré sa vyskytujú v náhodných časoch. Typickými príkladmi tokov sú poruchy v počítačových sieťach, hovory na telefónnych ústredniach, tok požiadaviek na opravu zariadení atď.
Prietok udalosti sa nazývajú stacionárne, ak pravdepodobnosť určitého počtu udalostí spadajúcich do časového intervalu dĺžky závisí len od dĺžky intervalu a nezávisí od umiestnenia časového intervalu na časovej osi.
Podmienka stacionárnosti je splnená tokom požiadaviek, ktorých pravdepodobnostné charakteristiky nezávisia od času. Najmä stacionárny tok je charakterizovaný konštantnou hustotou (priemerný počet požiadaviek za jednotku času). V praxi často dochádza k tokom žiadostí, ktoré (aspoň na obmedzený čas) možno považovať za stacionárne. Za pevnú linku možno považovať napríklad tok hovorov na mestskej telefónnej ústredni v časovom úseku od 12 do 13 hodín. Rovnaký tok v priebehu celého dňa už nemožno považovať za stacionárny (v noci je hustota hovorov výrazne nižšia ako cez deň).
Prietok udalosti sa nazývajú prúd bez následkov, ak pre akékoľvek neprekrývajúce sa časové obdobia počet udalostí pripadajúcich na jeden z nich nezávisí od počtu udalostí pripadajúcich na ostatné.
Podmienka absencie následného efektu – najdôležitejšia pre najjednoduchší tok – znamená, že aplikácie vstupujú do systému nezávisle od seba. Napríklad tok cestujúcich vstupujúcich do stanice metra možno považovať za tok bez následkov, pretože dôvody, ktoré určovali príchod jednotlivého cestujúceho v jednom konkrétnom okamihu a nie v inom, spravidla nesúvisia s podobnými dôvodmi pre iných cestujúcich. . Avšak podmienka bez následkov môže byť ľahko porušená kvôli objaveniu sa takejto závislosti. Napríklad tok cestujúcich opúšťajúcich stanicu metra už nemožno považovať za tok bez následných účinkov, pretože momenty odchodu cestujúcich prichádzajúcich tým istým vlakom sú navzájom závislé.
Prietok udalosti sa nazývajú obyčajný, ak je pravdepodobnosť výskytu dvoch alebo viacerých udalostí v krátkom časovom intervale t zanedbateľná v porovnaní s pravdepodobnosťou výskytu jednej udalosti (v tomto ohľade sa Poissonov zákon nazýva zákon zriedkavých udalostí).
Podmienka obyčajnosti znamená, že objednávky prichádzajú jednotlivo a nie v pároch, trojiciach atď. odchýlka rozptylu Bernoulliho rozdelenie
Napríklad tok zákazníkov vstupujúcich do kaderníckeho salónu možno považovať za takmer obyčajný. Ak pri mimoriadnom prietoku prichádzajú aplikácie iba v pároch, iba v trojiciach atď., potom sa mimoriadny prietok môže ľahko zredukovať na obyčajný; Na to stačí uvažovať o prúde párov, trojíc atď. namiesto prúdu jednotlivých požiadaviek. Bude to ťažšie, ak sa každá požiadavka môže náhodne ukázať ako dvojitá, trojitá atď. Potom musíte sa zaoberajú prúdom nie homogénnych, ale heterogénnych udalostí.
Ak má prúd udalostí všetky tri vlastnosti (t. j. stacionárny, obyčajný a nemá žiadny následný efekt), potom sa nazýva jednoduchý (alebo stacionárny Poissonov) prúd. Názov „Poisson“ je spôsobený skutočnosťou, že ak sú splnené uvedené podmienky, počet udalostí spadajúcich do akéhokoľvek pevného časového intervalu bude rozdelený na Poissonov zákon
Tu je priemerný počet udalostí A, ktoré sa zobrazujú za jednotku času.
Tento zákon je jednoparametrový, t.j. na jej nastavenie vám stačí poznať jeden parameter. Dá sa ukázať, že očakávanie a rozptyl v Poissonovom zákone sú číselne rovnaké:
Príklad. Povedzme, že uprostred pracovného dňa je priemerný počet žiadostí 2 za sekundu. Aká je pravdepodobnosť, že 1) za sekundu nebudú prijaté žiadne žiadosti, 2) do dvoch sekúnd príde 10 žiadostí?
Riešenie. Keďže platnosť aplikácie Poissonovho zákona je nepochybná a jeho parameter je daný (= 2), riešenie úlohy sa redukuje na aplikáciu Poissonovho vzorca (19.11).
1) t = 1, m = 0:
2) t = 2, m = 10:
Zákon veľkých čísel. Matematický základ pre skutočnosť, že hodnoty náhodnej premennej sa zhlukujú okolo niektorých konštantných hodnôt, je zákon veľkých čísel.
Historicky prvou formuláciou zákona veľkých čísel bola Bernoulliho veta:
„Pri neobmedzenom zvyšovaní počtu identických a nezávislých experimentov n frekvencia výskytu udalosti A konverguje v pravdepodobnosti k jej pravdepodobnosti,“ t.j.
kde je frekvencia výskytu udalosti A v n experimentoch,
Výraz (19.10) v podstate znamená, že pri veľkom počte experimentov sa frekvencia výskytu udalosti A môže nahradiť neznámu pravdepodobnosť tejto udalosti a čím väčší je počet vykonaných experimentov, tým je p* bližšie k p. Zaujímavý historický fakt. K. Pearson si hodil mincou 12 000-krát a jeho erb vyšiel 6019-krát (frekvencia 0,5016). Pri 24 000 vhodení tej istej mince dostal 12 012 erbov, t.j. frekvencia 0,5005.
Najdôležitejšou formou zákona veľkých čísel je Čebyševova veta: s neobmedzeným nárastom počtu nezávislých experimentov s konečným rozptylom a uskutočnených za rovnakých podmienok aritmetický priemer pozorovaných hodnôt náhodnej premennej konverguje v pravdepodobnosti k svojmu matematickému očakávaniu. V analytickej forme môže byť táto veta napísaná takto:
Čebyševova veta má okrem základného teoretického významu aj dôležité praktické aplikácie, napríklad v teórii merania. Po vykonaní n meraní určitej veličiny X, získate rôzne nezhodné hodnoty X 1, X 2, ..., xn. Pre približnú hodnotu meranej veličiny X vezmite aritmetický priemer pozorovaných hodnôt
pričom Čím viac experimentov sa vykoná, tým presnejší bude výsledok. Faktom je, že rozptyl množstva klesá s nárastom počtu vykonaných experimentov, pretože
D(X 1) = D(X 2)=…= D(xn) D(X), To
Vzťah (19.13) ukazuje, že aj pri vysokej nepresnosti meracích prístrojov (veľká hodnota), zvýšením počtu meraní, je možné získať výsledok s ľubovoľne vysokou presnosťou.
Pomocou vzorca (19.10) môžete nájsť pravdepodobnosť, že štatistická frekvencia sa neodchyľuje od pravdepodobnosti o viac ako


Príklad. Pravdepodobnosť udalosti v každom pokuse je 0,4. Koľko testov musíte vykonať, aby ste s pravdepodobnosťou nie menšou ako 0,8 očakávali, že relatívna frekvencia udalosti sa bude líšiť od pravdepodobnosti v absolútnej hodnote o menej ako 0,01?
Riešenie. Podľa vzorca (19.14)


preto sú podľa tabuľky dve aplikácie
teda, n 3932.
Rozsah variácií (alebo rozsah variácií) - toto je rozdiel medzi maximálnymi a minimálnymi hodnotami charakteristiky:
V našom príklade je rozsah variácie zmenového výkonu pracovníkov: v prvej brigáde R = 105-95 = 10 detí, v druhej brigáde R = 125-75 = 50 detí. (5 krát viac). To naznačuje, že výkon 1. brigády je „stabilnejší“, ale druhá brigáda má väčšie rezervy na zvýšenie výkonu, pretože Ak všetci pracovníci dosiahnu maximálny výkon pre túto brigádu, môže vyrobiť 3 * 125 = 375 dielov a v 1. brigáde len 105 * 3 = 315 dielov.
Ak extrémne hodnoty charakteristiky nie sú typické pre populáciu, potom sa použijú kvartilové alebo decilové rozsahy. Kvartilový rozsah RQ= Q3-Q1 pokrýva 50 % objemu populácie, prvý decilový rozsah RD1 = D9-D1 pokrýva 80 % údajov, druhý decilový rozsah RD2= D8-D2 – 60 %.
Nevýhodou ukazovateľa variačného rozsahu je, že jeho hodnota neodráža všetky výkyvy znaku.
Najjednoduchší všeobecný ukazovateľ odrážajúci všetky výkyvy charakteristiky je priemerná lineárna odchýlka, čo je aritmetický priemer absolútnych odchýlok jednotlivých opcií od ich priemernej hodnoty:
,
pre zoskupené údaje ![]() ,
,
kde xi je hodnota atribútu v diskrétnom rade alebo stred intervalu v intervalovom rozdelení.
Vo vyššie uvedených vzorcoch sa rozdiely v čitateli berú modulo, inak podľa vlastnosti aritmetického priemeru bude čitateľ vždy rovný nule. Preto sa priemerná lineárna odchýlka v štatistickej praxi používa zriedka, iba v prípadoch, keď sčítanie ukazovateľov bez zohľadnenia znamienka dáva ekonomický zmysel. S jeho pomocou sa analyzuje napríklad zloženie pracovnej sily, ziskovosť výroby, obrat zahraničného obchodu.
Rozmanitosť vlastnosti je priemerná štvorec odchýlok od ich priemernej hodnoty:
jednoduchý rozptyl ![]() ,
,
rozptyl vážený  .
.
Vzorec na výpočet rozptylu možno zjednodušiť:
Rozptyl sa teda rovná rozdielu medzi priemerom druhých mocnín opcie a druhou mocninou priemeru opcie populácie:  .
.
V dôsledku súčtu štvorcových odchýlok však rozptyl poskytuje skreslenú predstavu o odchýlkach, takže priemer sa vypočítava na základe neho smerodajná odchýlka, ktorý ukazuje, o koľko sa v priemere konkrétne varianty znaku odchyľujú od svojej priemernej hodnoty. Vypočítané ako druhú odmocninu rozptylu:
pre nezoskupené údaje  ,
,
pre variačné série 
Čím je hodnota rozptylu a smerodajnej odchýlky menšia, čím je populácia homogénnejšia, tým spoľahlivejšia (typickejšia) bude priemerná hodnota.
Priemerná lineárna a smerodajná odchýlka sú pomenované čísla, t.j. sú vyjadrené v merných jednotkách charakteristiky, sú obsahovo identické a významovo blízke.
Odporúča sa vypočítať absolútne odchýlky pomocou tabuliek.
Tabuľka 3 - Výpočet variačných charakteristík (na príklade obdobia údajov o zmenovom výkone pracovníkov posádky)
Počet pracovníkov |
Stred intervalu |
Vypočítané hodnoty |
|||||
Celkom: |
|||||||
Priemerný zmenový výkon pracovníkov: ![]()
Priemerná lineárna odchýlka: ![]()
Výrobný rozptyl: 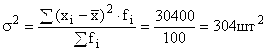
Smerodajná odchýlka výkonu jednotlivých pracovníkov od priemerného výkonu:
.
1 Výpočet rozptylu pomocou metódy momentov
Výpočet rozptylov zahŕňa ťažkopádne výpočty (najmä ak je priemer vyjadrený ako veľké číslo s niekoľkými desatinnými miestami). Výpočty je možné zjednodušiť použitím zjednodušeného vzorca a disperzných vlastností.
Disperzia má nasledujúce vlastnosti:
- Ak sa všetky hodnoty charakteristiky znížia alebo zvýšia o rovnakú hodnotu A, rozptyl sa nezníži:
 ,
,
 , potom alebo
, potom alebo 
Pomocou vlastností disperzie a najprv zmenšením všetkých variantov populácie o hodnotu A a následným delením hodnotou intervalu h dostaneme vzorec na výpočet disperzie vo variačných radoch s rovnakými intervalmi. svojím spôsobom: ,
,
kde je rozptyl vypočítaný pomocou metódy momentov;
h – hodnota intervalu variačného radu;
– možnosť nových (transformovaných) hodnôt;
A je konštantná hodnota, ktorá sa používa ako stred intervalu s najvyššou frekvenciou; alebo možnosť s najvyššou frekvenciou;  – druhá mocnina momentu prvého rádu;
– druhá mocnina momentu prvého rádu;
– moment druhého rádu.
Vypočítajme rozptyl pomocou metódy momentov na základe údajov o zmenovom výkone pracovníkov tímu.
Tabuľka 4 - Výpočet rozptylu pomocou metódy momentov
Skupiny výrobných pracovníkov, ks. |
Počet pracovníkov |
Stred intervalu |
Vypočítané hodnoty |
||
Postup výpočtu:


- Vypočítame rozptyl:
2 Výpočet rozptylu alternatívnej charakteristiky
Medzi charakteristikami, ktoré študuje štatistika, sú aj také, ktoré majú len dva vzájomne sa vylučujúce významy. Toto sú alternatívne znaky. Sú uvedené v dvoch kvantitatívnych hodnotách: možnosti 1 a 0. Frekvencia možnosti 1, ktorá je označená p, je podiel jednotiek s touto charakteristikou. Rozdiel 1-р=q je frekvencia možností 0.
xi |
|
Aritmetický priemer alternatívneho znamienka ![]() pretože p+q=1.
pretože p+q=1.
Alternatívny rozptyl vlastností
, pretože 1-R=q
Rozptyl alternatívnej charakteristiky sa teda rovná súčinu podielu jednotiek s touto charakteristikou a podielu jednotiek, ktoré túto charakteristiku nemajú.
Ak sa hodnoty 1 a 0 vyskytujú rovnako často, t.j. p=q, rozptyl dosahuje maximum pq=0,25.
Rozptyl alternatívneho atribútu sa používa vo výberových prieskumoch, napríklad kvality produktov.
3 Rozdiel medzi skupinami. Pravidlo sčítania odchýlky
Disperzia, na rozdiel od iných charakteristík variácie, je aditívna veličina. Teda v súhrne, ktorý je rozdelený do skupín podľa faktorových charakteristík X , rozptyl výslednej charakteristiky r možno rozložiť na rozptyl v rámci každej skupiny (v rámci skupín) a rozptyl medzi skupinami (medzi skupinami). Potom, spolu so štúdiom variácií vlastnosti v celej populácii ako celku, je možné študovať variácie v každej skupine, ako aj medzi týmito skupinami.
Celkový rozptyl meria variáciu vlastnosti pri v celom rozsahu pod vplyvom všetkých faktorov, ktoré túto odchýlku (odchýlky) spôsobili. Rovná sa strednej štvorcovej odchýlke jednotlivých hodnôt atribútu pri z veľkého priemeru a možno ho vypočítať ako jednoduchý alebo vážený rozptyl.
Medziskupinový rozptyl charakterizuje variáciu výsledného znaku pri spôsobené vplyvom faktora-znamenia X, ktoré tvorili základ zoskupenia. Charakterizuje variáciu skupinových priemerov a rovná sa strednej štvorci odchýlok skupinových priemerov od celkového priemeru:  ,
,
kde je aritmetický priemer i-tej skupiny;
– počet jednotiek v i-tej skupine (frekvencia i-tej skupiny);
– celkový priemer obyvateľstva.
Rozptyl v rámci skupiny odráža náhodnú variáciu, t. j. tú časť variácie, ktorá je spôsobená vplyvom nezapočítaných faktorov a nezávisí od atribútu faktora, ktorý tvorí základ zoskupenia. Charakterizuje variáciu individuálnych hodnôt vo vzťahu k skupinovým priemerom a rovná sa strednej štvorcovej odchýlke jednotlivých hodnôt atribútu pri v rámci skupiny z aritmetického priemeru tejto skupiny (priemer skupiny) a vypočíta sa ako jednoduchý alebo vážený rozptyl pre každú skupinu: ![]() alebo
alebo ![]() ,
,
kde je počet jednotiek v skupine.
Na základe rozdielov v rámci skupiny pre každú skupinu je možné určiť celkový priemer odchýlok v rámci skupiny:
.
Vzťah medzi tromi disperziami je tzv pravidlá pre pridávanie odchýlok, podľa ktorého sa celkový rozptyl rovná súčtu rozptylu medzi skupinami a priemeru rozptylov v rámci skupiny:
Príklad. Pri skúmaní vplyvu tarifnej kategórie (kvalifikácie) pracovníkov na úroveň ich produktivity práce boli získané nasledovné údaje.
Tabuľka 5 – Rozdelenie pracovníkov podľa priemerného hodinového výkonu.
№ p/p |
Pracovníci 4. kategórie |
Pracovníci 5. kategórie |
|||||
Výkon |
Výkon |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
V tomto príklade sú pracovníci rozdelení do dvoch skupín podľa faktorových charakteristík X– kvalifikácie, ktoré sú charakterizované ich hodnosťou. Výsledný znak – produkcia – sa mení pod jeho vplyvom (medziskupinová variácia), ako aj v dôsledku iných náhodných faktorov (vnútroskupinová variácia). Cieľom je merať tieto variácie pomocou troch variácií: celkových, medzi skupinami a v rámci skupín. Empirický koeficient determinácie ukazuje podiel variácií vo výslednej charakteristike pri pod vplyvom faktorového znaku X. Zvyšok celkovej variácie pri spôsobené zmenami iných faktorov.
V tomto príklade sa empirický koeficient determinácie rovná: ![]() alebo 66,7 %,
alebo 66,7 %,
To znamená, že 66,7 % variácií v produktivite pracovníkov je spôsobených rozdielmi v kvalifikácii a 33,3 % je spôsobených vplyvom iných faktorov.
Empirický korelačný vzťah ukazuje úzke prepojenie medzi zoskupovaním a výkonnostnými charakteristikami. Vypočítané ako druhá odmocnina empirického koeficientu determinácie:
Empirický korelačný pomer, ako napríklad , môže nadobúdať hodnoty od 0 do 1.
Ak nie je spojenie, potom = 0. V tomto prípade = 0, to znamená, že priemery skupín sú navzájom rovnaké a neexistuje žiadna medziskupinová variácia. To znamená, že zoskupovacia charakteristika - faktor neovplyvňuje tvorbu všeobecnej variácie.
Ak je spojenie funkčné, potom =1. V tomto prípade sa rozptyl priemerov skupiny rovná celkovému rozptylu (), to znamená, že neexistuje žiadna odchýlka v rámci skupiny. To znamená, že charakteristika zoskupenia úplne určuje variáciu výslednej charakteristiky, ktorá sa skúma.
Čím je hodnota korelačného pomeru bližšie k jednote, tým bližšie, bližšie k funkčnej závislosti, je spojenie medzi charakteristikami.
Na kvalitatívne posúdenie tesnosti súvislostí medzi charakteristikami sa používajú Chaddockove vzťahy.
V príklade ![]() , čo naznačuje úzku súvislosť medzi produktivitou pracovníkov a ich kvalifikáciou.
, čo naznačuje úzku súvislosť medzi produktivitou pracovníkov a ich kvalifikáciou.
Spolu so štúdiom variácií charakteristiky v celej populácii ako celku je často potrebné sledovať kvantitatívne zmeny v charakteristike v skupinách, do ktorých je populácia rozdelená, ako aj medzi skupinami. Táto štúdia variácie sa dosahuje výpočtom a analýzou rôznych typov rozptylu.
Existujú celkové, medziskupinové a vnútroskupinové odchýlky.
Celkový rozptyl σ 2 meria variáciu vlastnosti v celej populácii pod vplyvom všetkých faktorov, ktoré túto variáciu spôsobili.
Medziskupinová variácia (δ) charakterizuje systematickú variáciu, t.j. rozdiely v hodnote skúmaného znaku, ktoré vznikajú pod vplyvom faktorového znaku, ktorý tvorí základ skupiny. Vypočíta sa pomocou vzorca: 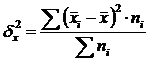 .
.
Rozptyl v rámci skupiny (σ) odráža náhodné variácie, t.j. časť variácie, ktorá sa vyskytuje pod vplyvom nezapočítaných faktorov a nezávisí od atribútu faktora, ktorý tvorí základ skupiny. Vypočítava sa podľa vzorca: 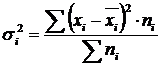 .
.
Priemer odchýlok v rámci skupiny:  .
.
Existuje zákon spájajúci 3 typy rozptylu. Celkový rozptyl sa rovná súčtu priemeru rozptylu v rámci skupiny a medzi skupinami: ![]() .
.
Tento pomer sa nazýva pravidlo pre pridávanie odchýlok.
Široko používaným ukazovateľom v analýze je podiel rozptylu medzi skupinami na celkovom rozptyle. Volá sa empirický koeficient determinácie (η 2): .
Druhá odmocnina empirického koeficientu determinácie sa nazýva empirický korelačný pomer (η):
 .
.
Charakterizuje vplyv charakteristiky, ktorá tvorí základ skupiny, na variáciu výslednej charakteristiky. Empirický korelačný pomer sa pohybuje od 0 do 1.
Jeho praktické využitie si demonštrujeme na nasledujúcom príklade (tabuľka 1).
Príklad č.1. Tabuľka 1 - Produktivita práce dvoch skupín pracovníkov v jednej z dielní NPO Cyclone
Vypočítajme celkové a skupinové priemery a odchýlky:
Počiatočné údaje na výpočet priemeru vnútroskupinového a medziskupinového rozptylu sú uvedené v tabuľke. 2.
tabuľka 2
Výpočet a δ 2 pre dve skupiny pracovníkov.
|
Pracovné skupiny | Počet robotníkov, ľudí | Priemer, deti/zmena | Disperzia |
| Absolvované technické školenie | 5 | 95 | 42,0 |
| Tí, ktorí neabsolvovali technické školenie | 5 | 81 | 231,2 |
| Všetci pracovníci | 10 | 88 | 185,6 |
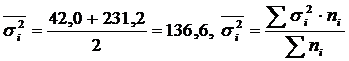 .
.
Medziskupinový rozptyl
Celkový rozptyl:
Teda empirický korelačný pomer: .
Spolu s variáciami v kvantitatívnych charakteristikách možno pozorovať aj variácie v kvalitatívnych charakteristikách. Táto štúdia variácií sa dosiahne výpočtom nasledujúcich typov rozptylov:
Rozptyl podielu v rámci skupiny je určený vzorcom
Kde n i– počet jednotiek v samostatných skupinách.Podiel študovanej charakteristiky v celej populácii, ktorý je určený vzorcom:
Tieto tri typy rozptylu spolu súvisia takto:
Tento vzťah rozptylov sa nazýva teorém o sčítaní rozptylov podielu vlastnosti.